
Один флагман заточений під автономну роботу з інструментами, інший під складний код та акуратні відповіді без зайвої самовпевненості.

У квітні 2026 року ринок великих мовних моделей одержав рідкісний сюжет без натяжки. 16 квітня Anthropic випустила Claude Opus 4.7. За тиждень, 23 квітня, OpenAI відповіла GPT-5.5. Дві лабораторії, дві старші моделі, один тиждень між анонсами. Для галузі, де кожен новий випуск зазвичай намагаються продати як «історичний», цього разу історичність не довелося натягувати на прес-реліз.
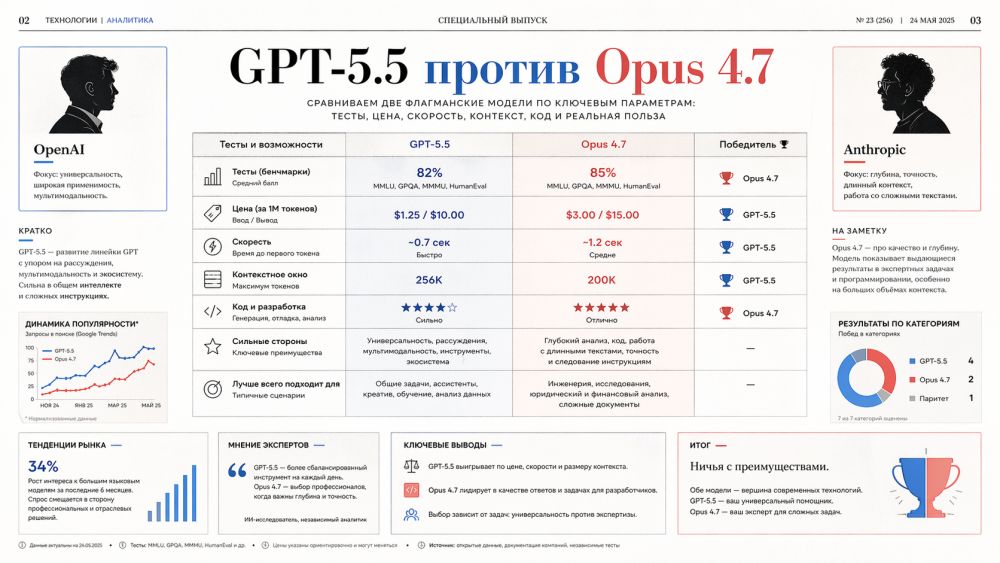
Порівняння вийшло неприємним всім, хто любить прості відповіді. GPT-5.5 помітно сильніший у завданнях, де модель має діяти як виконавець: тримати план, користуватися інструментами, керувати середовищем, не кидати роботу на середині. Claude Opus 4.7 виглядає переконливіше там, де потрібна акуратна інженерна робота, суворе дотримання інструкції та спокійна чесність замість впевненого вигадування. Переможець є, але якщо заздалегідь назвати завдання.
Головний висновок звучить нудно, зате корисно: епоха «однієї кращої моделі на все» закінчилася. Далі компанії будуть збирати набори з кількох моделей, а не сперечатися про єдину корону. GPT-5.5 та Opus 4.7 хороші не однаково. У цьому й починається справжня інтрига.
Що взагалі сталося за ці сім днів
Claude Opus 4.7 вийшов для Anthropic не просто як чергове вдосконалення. Компанія кілька місяців жила під роздратований шум розробників, які скаржилися на деградацію попередніх версій Claude. Користувачі говорили, що модель стала обережнішою, частіше втрачає нитку в довгих завданнях і гірше тримає складну інженерну роботу. Anthropic заперечувала навмисне ослаблення моделі, але саме тло було неприємне: коли розробники перестають довіряти інструменту, красиві графіки не лікують репутацію.
Opus 4.7 став відповіддю на цей біль. В офіційному описі Anthropic наголошує на складні завдання за кодом, довгі робочі цикли, суворіші інструкції, покращений зір і здатність перевіряти власні дії перед фінальною відповіддю. Модель отримала підтримку зображень до 2576 пікселів по довжині, тобто приблизно до 3,75 мегапікселя. Для читання щільних схем, скріншотів інтерфейсів, таблиць і діаграм таке зростання важливіше, ніж чергове красиве формулювання про «інтелект».
OpenAI вийшла через тиждень з іншою тезою. GPT-5.5 в анонсі описують як модель для «реальної роботи за комп’ютером»: код, дослідження, аналіз даних, документи, таблиці, програми та перехід між інструментами до завершення завдання. Менше ручного супроводу, більше за самостійний рух. Якщо Opus 4.7 обіцяє бути дуже сильним інженером, GPT-5.5 намагається стати співробітником, якому можна доручити заплутаний шматок роботи і не стояти над душею.
| Параметр | GPT-5.5 | Клод Опус 4.7 |
|---|---|---|
| Дата випуску | 23 квітня 2026 року | 16 квітня 2026 року |
| Головна ставка | Агентна робота, управління інструментами, складні багатокрокові завдання | Код, суворі інструкції, перевірка власних висновків, робота із зображеннями |
| Ціна вхідних токенів | 5 доларів за мільйон | 5 доларів за мільйон |
| Ціна вихідних токенів | 30 доларів за мільйон | 25 доларів за мільйон |
| Контекст | До 1 мільйона токенів | До 1 мільйона токенів |
| Головний ризик для бюджету | Висока ціна вихідних токенів, особливо у версії Pro | Новий розбір тексту на токени може збільшити фактичну витрату |
GPT-5.5: модель, яка хоче працювати, а не відповідати
Найсильніша частина GPT-5.5 не в тому, що модель краще пише пояснення чи акуратніше тримає стиль. Головна заявка OpenAI лежить в іншому місці. Модель повинна брати погано оформлене завдання, сама уточнювати план через дії, користуватися інструментами, перевіряти проміжний результат і доводити до кінця роботу. Не «ось вам порада», а «ось готовий набір змін, звіт, таблиця, перевірка та наступний крок».
Тому GPT-5.5 особливо цікаво дивитися не як чат-бот, а як виконавець у середовищі. У Codex модель, за даними OpenAI, краще справляється з впровадженням змін, переробкою коду, пошуком помилок, перевірками та перенесенням правок через кілька частин проекту. Ранні тестувальники описували саме це зрушення: GPT-5.5 довше тримає завдання, менше зупиняється раніше часу і краще передбачає, які перевірки знадобляться перед здаванням роботи.
Тут важлива не лише «розумність», а й витривалість. Багато моделей красиво стартують: пишуть план, створюють перші файли, бадьоро пояснюють хід думки. Проблеми починаються на двадцятій хвилині, коли треба пов’язати зміни, виправити побічний збій, повторно прогнати перевірку та не забути вихідну мету. GPT-5.5 б’є саме у цю зону. Для бізнесу така здатність дорожча за красиву відповідь на одне складне питання.
Opus 4.7: реванш Anthropic у інженерній роботі
Claude Opus 4.7 виглядає менш видовищно, якщо чекати від моделі образу універсального цифрового співробітника. Зате Anthropic явно цілилася у розробників, аналітиків та команди, які вже використовують Claude у серйозній роботі та втомилися від маленьких, але дорогих провалів. Модель стала точніше дотримуватися інструкцій, краще ловить протиріччя і частіше каже, що даних не вистачає, замість підставляти правдоподібну вигадку.
Для інженерної роботи така поведінка критична. Погана модель не завжди та, що помилилася. Набагато небезпечніша модель, яка помилилася впевнено, гарно загорнула помилку в пояснення і змусила людину повірити. У цьому сенсі похвала Opus 4.7 від ранніх користувачів звучить практично: менше зайвих обгорток у коді, менше безглуздих запасних гілок, більше перевірки перед виконанням. Чи не вау-ефект на сцені, а менше бруду в робочому проекті.
Anthropic в анонсі окремо підкреслює, що Opus 4.7 сильніший за колишню версію в довгих завданнях, краще використовує файлову пам’ять і точніше працює із зображеннями високої роздільної здатності. Компанія також додала рівні зусилля та «бюджети завдань»: розробник може задати межу витрати токенів на довгий цикл, а модель має розподілити ресурс між роздумом, викликами інструментів та фінальною відповіддю. Ідея здорова: якщо не поставити ліміт, старші моделі іноді міркують так, ніби рахунок оплачує хтось інший. Зазвичай так і є, доки не приходить рахунок.
Де сухі цифри ламають просту картину
Таблиця тестів швидко охолоджує бажання оголосити переможця. GPT-5.5 впевнено забирає сценарії, де треба керувати середовищем, діяти через інструменти та виконувати довгі ланцюжки. Opus 4.7 сильніше виглядає у реальних завданнях за кодом з репозиторіїв та міркуваннях без зовнішніх інструментів. Різниця не косметична, але й тотальна.
З тестами треба поводитися акуратно. Лабораторії самі обирають умови, режими міркування, набори завдань та конкурентів для порівняння. Частина оцінок йде з внутрішніх випробувань, частина з публічних наборів, частина із незалежних таблиць. Тому чесніше читати цифри як картку спеціалізацій, а не як спортивну таблицю чемпіонату світу.
| Тест | Що перевіряє | GPT-5.5 | Клод Опус 4.7 | Практичний зміст |
|---|---|---|---|---|
| Термінал-Бенч 2.0 | Робота в командному рядку, планування, інструменти | 82,7% | 69,4% | GPT-5.5 сильніший як виконавець у технічному середовищі |
| SWE-bench Pro | Реальні завдання з GitHub | 58,6% | 64,3% | Opus 4.7 найкраще підходить для складних завдань за кодом |
| Перевірено OSWorld | Управління реальним комп’ютерним середовищем | 78,7% | 78,0% | Майже нічия, формально попереду GPT-5.5 |
| Humanity’s Last Exam без інструментів | Складні питання без зовнішньої допомоги | 41,4% | 46,9% | Opus 4.7 краще розмірковує у закритому режимі |
| FrontierMath Рівень 4 | Дуже складна математика | 35,4% | 22,9% | GPT-5.5 помітно сильніший на важкій математиці |
| Атлас МКП | Організація роботи з інструментами | 75,3% | 79,1% | Opus 4.7 краще в частині зв’язування інструментів з цього тесту |
| MRCR версії 2, 512 тис.-1 млн. | Пошук та утримання відомостей у величезному контексті | 74,0% | 32,2% | GPT-5.5 різко додав у довгому контексті |
Найважливіший результат для GPT-5.5 – Terminal-Bench 2.0. 82,7% проти 69,4% у Opus 4.7 показують, що OpenAI справді просунулась у завданнях, де модель не просто відповідає, а діє. Такий клас завдань ближчий до майбутніх робочих агентів, ніж звичне листування в чаті.
Найнеприємніший для OpenAI результат – SWE-bench Pro. Там Opus 4.7 набирає 64,3% проти 58,6% GPT-5.5. Для розробника цей тест звучить приземлене багатьох академічних наборів: виправити реальне завдання в реальному проекті, не втратити залежності, не зламати сусідні частини. Якщо команда вибирає модель для важкого коду, Opus 4.7 не можна списувати навіть після гучного виходу GPT-5.5.
Гроші: прайс-лист бреше не тому, що бреше
На перший погляд Claude Opus 4.7 дешевша. Вхідні токени у обох моделей коштують однаково, по $5 за мільйон, а ті, що виходять у Opus 4.7, коштують $25 проти $30 у GPT-5.5. Різниця 17% на користь Anthropic. Для великих обсягів такий розрив вже схожий на фінансовий аргумент, а не на дріб’язок у таблиці.
Але ціна за токен та ціна готового завдання – різні речі. У Opus 4.7 з’явився новий спосіб розбирати текст на токени. Токен – це фрагмент тексту, за який модель вважає вартість та обсяг роботи. Anthropic прямо пише, що те саме введення може перетворюватися в 1,0-1,35 разу більше токенів залежно від типу даних. Для звичайного тексту приріст може бути майже непомітним, а для коду, таблиць, розмітки та структурованих даних рахунок здатний зрости вже відчутно.
GPT-5.5 має зворотну історію. OpenAI підняла ціну в порівнянні з GPT-5.4, але одночасно стверджує, що модель витрачає менше токенів на виконання тих же завдань у Codex і частіше досягає результату без повторних прогонів. Якщо дорога модель заощаджує два зайві запуски та одну годину інженера, формальний прайс-лист перестає бути головним аргументом.
| Сценарій | Що дивитися у рахунку | Хто виглядає вигідніше |
|---|---|---|
| Багато коротких відповідей | Ціна вихідних токенів та ліміти підписки | Найчастіше Opus 4.7 |
| Довгий агентний цикл | Кількість повторних запусків, урвища, виправлення | Найчастіше GPT-5.5 |
| Код та структуровані дані | Фактичне зростання числа токенів після переходу на Opus 4.7 | Потрібно міряти на своєму трафіку |
| Завдання з дорогою помилкою | Ціна перевірки людиною та вартість невірного висновку | Залежить від предметної галузі |
| Потік дешевих типових завдань | Чи потрібна взагалі старша модель | Найчастіше жодна з двох |
Найдоросліша стратегія має такий вигляд: не вибирати модель за ціною в таблиці, а прогнати свій набір завдань через обидві системи. Вважати треба не вартість мільйона токенів, а вартість результату. Скільки запитів пішло на готову відповідь. Скільки разів людина виправляла модель. Скільки завдань довелося перезапускати. Скільки помилок пройшли далі ланцюжком. Без такої перевірки суперечка про ціну перетворюється на ворожіння на рекламних сторінках.
Яку модель брати для коду
Для розробки відповіді залежить від типу роботи. Якщо потрібно виправляти реальні завдання у великих репозиторіях, акуратно дотримуватись правил проекту, не плодити зайві абстракції та чесно визнавати нестачу даних, Claude Opus 4.7 виглядає сильним першим вибором. SWE-bench Pro підтверджує це цифрами, а відгуки ранніх користувачів сходяться в одному: модель стала суворішою, ретельною і менше намагається «догодити» за будь-яку ціну.
Якщо потрібно доручити моделі довгу роботу в середовищі, де треба ходити файлами, запускати перевірки, змінювати кілька частин проекту і тримати загальний план, GPT-5.5 виглядає небезпечно сильним кандидатом. Terminal-Bench 2.0 та заяви OpenAI про Codex вказують саме на такий профіль. Модель краще підходить для завдань, де важлива не лише точність окремого виправлення, а й здатність тягнути робочий процес до кінця.
Тому для команди розробки розумна схема виглядає не як «обрали одну модель та забули», а як маршрутизацію. Opus 4.7 – на складний розбір коду, перевірку архітектурних рішень, пошук прихованих помилок, суворі інструкції. GPT-5.5 – на довгі ланцюжки дій, масові зміни, зв’язок коду з документами, перевірками та робочими інструментами. Молодші моделі – на чернетки, прості пояснення та рутинні завдання, де старший флагман просто спалює бюджет.
Де GPT-5.5 виглядає особливо сильною
GPT-5.5 виграє там, де завдання погано міститься в один запит. Наприклад, «розбери шість місяців заявок, знайди причини відмов, що повторюються, збери таблицю, запропонуй правила маршрутизації і перевір прикордонні випадки». Старі моделі часто добре виконували перший шматок, потім починали втрачати мету. GPT-5.5 створювали саме для таких ланцюжків.
OpenAI наводить показовий внутрішній приклад: фінансова команда використовувала Codex з GPT-5.5 для перевірки 24771 податкової форми K-1 на 71637 сторінках, прибравши персональні дані з процесу. Робота прискорилася на два тижні, порівняно з минулим роком. Навіть якщо ставитись до корпоративних прикладів з холодною головою, клас завдання зрозумілий: великий обсяг документів, багато кроків, потрібна перевірка, результат має лягти у робочий процес.
Ще одна сильна зона – довгий контекст. На MRCR v2 при діапазоні 512 тисяч – 1 мільйон токенів GPT-5.5 отримала 74,0% проти 36,6% у GPT-5.4. Такий стрибок важливий для юридичних архівів, внутрішніх баз знань, великих листування, довгих технічних звітів та дослідницьких матеріалів. Але довгий контекст не скасовує перевірку: модель може утримувати більше відомостей, але людина все одно мусить розуміти, які висновки критичні.
Де Opus 4.7 може бути кращим
Opus 4.7 особливо цікавий там, де модель має бути не гучною, а надійною. Розбір складної задачі за кодом, пошук логічної помилки, робота з суперечливими даними, акуратна перевірка виведення, створення інтерфейсів та документів з гарною структурою – все це лежить у зоні сили Anthropic. У тестах і відгуках знову і знову з’являється одна думка: Opus 4.7 менше вдає, що знає відповідь.
Для аналітика або інженера така риса дорожча за ефектний стиль. Коли модель повідомляє “даних не вистачає”, робота сповільнюється на хвилину, але система не отримує фальшивий висновок. Коли модель підставляє правдоподібне значення, помилка йде у документ, код, розрахунок чи лист клієнту. Потім помилку шукають уже люди, зазвичай у поганому настрої.
Поліпшений зір Opus 4.7 також не декоративна функція. Модель може читати більш щільні зображення, а значить краще працювати зі складними скріншотами, діаграмами, інтерфейсами, технічними схемами та документами, де важливі дрібні елементи. Для завдань комп’ютерного управління, перевірки макетів та вилучення даних із візуальних матеріалів таке зростання дозволу дає практичну користь.
Mythos Preview: третій гравець, якого не можна просто ігнорувати
Порівняння GPT-5.5 та Opus 4.7 ускладнює третя модель Anthropic – Claude Mythos Preview. Широкого доступу до неї немає. За даними Axios , Anthropic прямо визнає, що Opus 4.7 поступається Mythos за загальною потужністю, але тримає більш сильну модель в обмеженому доступі через ризик кібербезпеки.
Ця деталь змінює політичний сенс перегонів. OpenAI виводить GPT-5.5 на ринок і робить ставку на поширення при посилених обмеженнях. Anthropic випускає Opus 4.7 як публічний флагман, але найсильніший козир залишає за зачиненими дверима. Для клієнтів доступна модель важливіша за міфічну надмодель, але для стратегічних перегонів питання залишається відкритим.
За даними VentureBeat , GPT-5.5 вузько обходить Mythos Preview на Terminal-Bench 2.0: 82,7% проти 82,0%. На Humanity’s Last Exam без інструментів Mythos Preview набирає 56,8%, тоді як Opus 4.7 отримує 46,9%, а GPT-5.5 Pro – 43,1%. Виходить дивна картина: OpenAI сильніше у публічному агентному продукті, Anthropic, можливо, тримає потужнішу систему у запасі.
Безпека стала частиною продукту, а не виноскою
Обидва випуски показують новий порядок речей. Сильну модель вже не можна просто викотити і сказати «користуйтесь». Чим краще система пише код, шукає помилки, керує інструментами та розмірковує про біологію чи хімію, тим більше питань до доступу, фільтрів та перевірки користувачів. Безпека перестала бути нудним розділом наприкінці анонсу. Тепер безпека впливає на те, хто отримає модель, у якому режимі та з якими обмеженнями.
OpenAI пише, що GPT-5.5 отримала найсуворіші на момент випуску заходи захисту компанії, включаючи жорсткіші класифікатори для кіберрисків. Компанія заздалегідь попереджає, що частина користувачів може зіткнутися з дратівливими відмовими, доки обмеження налаштовуватимуть. Визнання неприємне, зате чесне: що сильніша модель, то вища ймовірність помилкових спрацьовувань на межі легітимного дослідження безпеки.
Anthropic використовує Opus 4.7 як випробувальний полігон для обмежувачів, які в майбутньому можуть допомогти випустити моделі Mythos класу ширше. В Opus 4.7 вбудовано блокування для заборонених та високоризикових кіберсценаріїв, а фахівці з безпеки можуть проходити окрему перевірку для розширеного доступу. Ринок поступово приходить до моделі “сильні можливості плюс перевірений доступ”. Старий підхід «один чат для всіх завдань» тріщить під вагою своїх можливостей.
Практичний вибір без релігійної війни
Якщо потрібна коротка рекомендація, то GPT-5.5 варто перш за все пробувати для багатокрокових завдань, автоматизації робочих процесів, аналізу великих масивів документів, управління інструментами та завдань, де модель має дійти результату майже як виконавець. Особливо, якщо команда вже живе в екосистемі OpenAI і використовує Codex, ChatGPT Business або Enterprise.
Claude Opus 4.7 варто насамперед пробувати для складного коду, суворого аналізу, перевірки суперечливих даних, роботи з великими проектами та сценаріїв, де впевнена помилка коштує дорожче за повільну відповідь. Особливо якщо команда вже використовує Claude Code, цінує буквальне дотримання інструкцій і хоче менше «гарних здогадів».
| Завдання | Найкращий перший кандидат | Чому |
|---|---|---|
| Довга автоматизація з кількома інструментами | GPT-5.5 | Сильніше в агентних сценаріях та роботі з комп’ютерним середовищем |
| Складне виправлення у репозиторії | Клод Опус 4.7 | Найкраще результат на SWE-bench Pro та сильна репутація в інженерних завданнях |
| Аналіз величезного набору документів | GPT-5.5 | Різке зростання на довгому контексті та гарна зв’язка з робочими інструментами |
| Перевірка коду та пошук тонких помилок | Клод Опус 4.7 | Ставка на точність, самоперевірку та чесне визнання обмежень |
| Математика високого рівня | GPT-5.5 | Помітна перевага на FrontierMath Tier 4 |
| Міркування без інструментів | Клод Опус 4.7 | Вище результат на Humanity’s Last Exam без інструментів |
| Дешева рутина | Жодна зі старших моделей | Краще брати молодші моделі та не платити за зайву потужність |
Найкращий практичний хід – зібрати 30-50 реальних завдань своєї команди та прогнати через обидві моделі. Чи не демо-запити, не красиві загадки, не «напиши змійку мовою Python», а справжні робочі випадки: брудна таблиця, старий модуль, спірний документ, довге листування, неповне технічне завдання, завдання з суперечливими вступними. Після такого тесту суперечка швидко стане тихішою.
Що перевірити перед переходом
Перехід на старшу модель без виміру майже гарантує сюрпризи. Потрібно вважати не лише якість відповідей, а й ціну, затримку, кількість повторів, кількість ручних виправлень та типові відмови. Для Opus 4.7 окремо варто виміряти зростання кількості токенів на своїх даних. Для GPT-5.5 окремо варто перевірити, чи агентська автономність окупає більш дорогий вихід.
Командам розробки корисно тримати два кошики завдань. У першій – завдання, де модель повинна дати точний висновок чи редагування. У другій – завдання, де модель має виконати ланцюжок дій. Opus 4.7 частіше виграє у першому кошику, GPT-5.5 частіше виграє у другому. Спроба оцінювати обидві моделі одним усередненим балом просто зітре головну різницю.
- Візьміть реальні завдання протягом останніх двох тижнів, а не штучні приклади.
- Порівняйте результат, кількість повторних запусків та обсяг ручної редагування.
- Окремо порахуйте вхідні та вихідні токени.
- Перевірте, як модель поводиться при нестачі даних.
- Подивіться, де модель впевнено помиляється, а де чесно зупиняється.
- Не віддавайте старшим моделям дешеву рутину без причини.
Підсумок: корона тепер лежить не на голові, а у маршрутизаторі
GPT-5.5 не вбила Claude Opus 4.7. Claude Opus 4.7 не пережив тиждень і не став вчорашньою новиною. Порівняння вийшло набагато цікавіше. OpenAI сильніше рухає ідею моделі-виконавця, яка бере складну роботу та тягне процес через інструменти. Anthropic сильніше захищає образ моделі-інженера, яка акуратно працює з кодом, краще тримає інструкцію і менше бреше впевненим голосом.
Для користувача хороша відповідь тепер звучить не “бери GPT” і не “бери Claude”. Хороша відповідь звучить так: маршрутизуй. Надсилай агентні ланцюжки та довгі робочі процеси в GPT-5.5. Надсилай складний код, строгий аналіз та завдання з високою ціною впевненої помилки в Opus 4.7. Для найпростіших завдань використовуй молодші моделі. Для критичних висновків залишай людську перевірку, бо жодна таблиця тестів не скасовує відповідальності.
Квітень 2026 показав не просто гонку двох лабораторій. Ринок став дорослішим. Старші моделі більше не відрізняються лише «розумнішими» і «ще розумнішими». Вони набувають характеру, профілю, ціни помилки та власної економіки. Корона більше не належить до однієї моделі. Корона лежить у системі, яка вміє вибрати правильну модель для правильного завдання.
